数据存储与计算 从数据库选型到Lambda与Kappa架构
在数据科学的学习过程中,数据存储与计算是构建整个数据处理流程的核心环节。本课程作为数据科学入门系列的第二部分,将聚焦于数据存储与计算的整体流程、数据库选型,以及Lambda与Kappa架构的对比,帮助初学者建立系统的知识框架。
整体流程与概念
数据存储与计算的整体流程通常包括数据采集、存储、处理、分析和输出。从原始数据到最终洞察,关键在于如何高效地管理和计算数据。计算部分涉及批处理(如Hadoop)和流处理(如Spark Streaming),而存储则需考虑数据的结构、规模和访问模式。理解这一流程有助于选择合适的技术栈,避免数据孤岛和性能瓶颈。
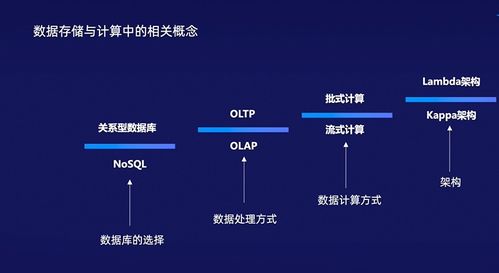
数据库的选型
数据库选型是数据存储的关键决策,需根据数据特性、查询需求和扩展性来确定。常见类型包括:
- 关系型数据库(如MySQL、PostgreSQL):适合结构化数据,支持ACID事务,适用于事务处理系统。
- NoSQL数据库(如MongoDB、Cassandra):处理非结构化或半结构化数据,支持高可扩展性和灵活模式,常用于大数据场景。
- 数据仓库(如Amazon Redshift、Snowflake):专为分析和查询优化,适用于OLAP(在线分析处理)。
选型时需考虑数据量、读写频率、一致性要求和成本,例如,高并发场景可选NoSQL,而复杂分析则倾向数据仓库。
架构:Lambda vs Kappa
Lambda和Kappa是两种常见的数据处理架构,用于解决批处理和流处理的融合问题。
- Lambda架构:结合批处理层和速度层(流处理层),批处理层处理历史数据以保证准确性,速度层处理实时数据以降低延迟。优点是容错性强,但维护复杂,需同步两套逻辑。
- Kappa架构:简化Lambda,仅依赖流处理层,通过重放数据流来处理历史和实时数据。优点是架构简单、易于维护,但对流处理引擎要求高,如Apache Kafka。
选择时,若需高实时性和简化运维,Kappa更优;若对数据准确性有极高要求,Lambda可能更合适。
数据分析和存储服务
现代数据分析和存储服务(如AWS S3、Google BigQuery)提供了托管解决方案,简化了基础设施管理。这些服务支持弹性扩展、集成计算引擎(如Spark),并降低运维成本。在实践中,结合云服务可以加速数据流水线的构建,例如使用S3存储原始数据,通过Lambda或Kappa架构进行计算,最终在分析服务中生成报告。
数据存储与计算是数据科学的基础,掌握整体流程、合理选型数据库,并理解架构差异,能有效提升数据处理效率。建议初学者从实际项目入手,逐步应用这些概念,以深化理解。
如若转载,请注明出处:http://www.xspush.com/product/29.html
更新时间:2025-11-29 06:10:28